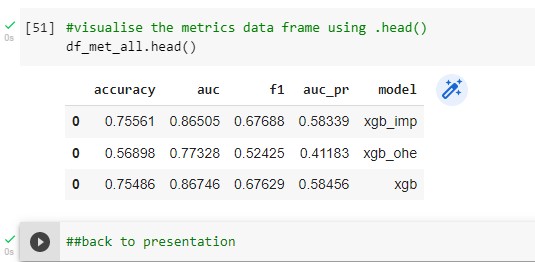
The xgb_imp model has a slightly higher accuracy while the xgb model has a slightly higher AUC. So, how can we decide which is a “better” model in this case? Also, is there any reason that xgb has higher AUC than xgb_imp? Or is that just random, and maybe with some different data I can get AUC higher in xgb_imp for this same set of features?
Lastly, xgb_ohe does considerably worse job here, why is that? Is that because of overfitting? I think the ohe should do a better job dealing with categorical data such as states and cities rather than labeling. Also, the combination of the two of them should work even better, right? But, I don’t think any of those two method do a good job dealing with the ‘city’ column, as ohe would make way too many features and labelling is going to assert that they have some sort of order, I think. Maybe the frequency-one could help here? Can you explain?
